The Complete Guide to llms.txt: Should You Care About This AI Standard?
 Bob Mitro
Bob MitroThere's a new file causing arguments across tech Twitter, SEO communities, and developer forums. It's called llms.txt, and depending on who you ask, it's either the future of how AI systems discover your content — or a complete waste of time.
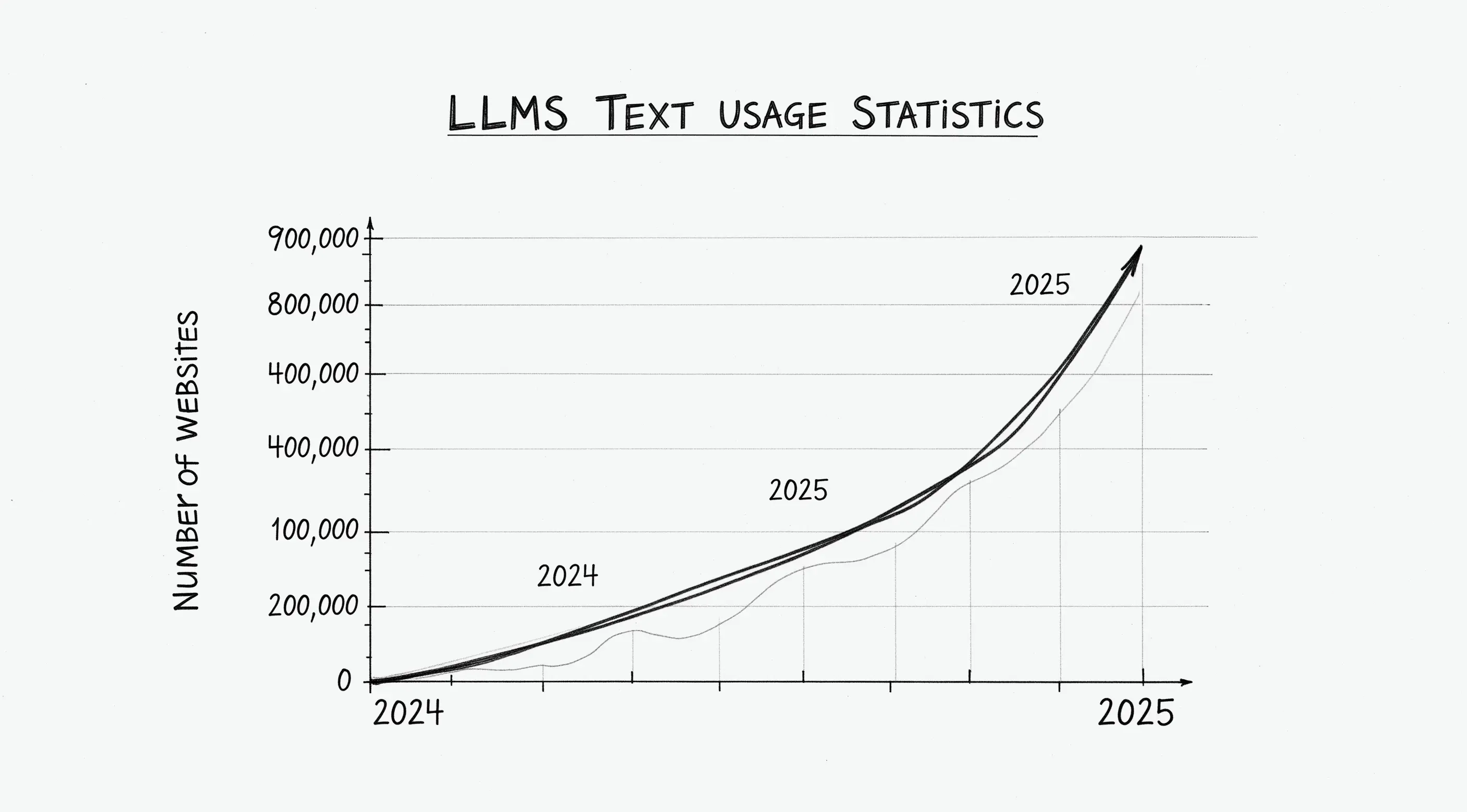
Here's what makes this weird: over 844,000 websites have already implemented it — according to BuiltWith's tracking as of October 25, 2025. Major companies like Anthropic (Claude docs), Cloudflare, and Stripe are using it. Yet not a single major AI platform has officially said they actually read these files.
Yeah. Think about that for a second.
So what's going on?
The Problem This Tries to Solve
Picture this: someone asks ChatGPT or Claude a question about your product. The AI needs to fetch information from your website right now, while answering.
But there's a problem.
Your website has navigation menus, cookie banners, footers, sidebars, JavaScript-heavy layouts, and marketing copy scattered everywhere. The actual useful information? Buried somewhere in all that noise. And the AI only has seconds to find it, plus limited "context window" space to work with.
This is fundamentally different from how Google works. Google crawls your site over days or weeks, indexes everything, serves cached results. AI systems need to grab content in real-time during conversations with users. It's messy. Resource-intensive. Often inaccurate.
Enter llms.txt — a simple text file you place at yourdomain.com/llms.txt that essentially says: "Hey AI, skip all the clutter. Here are my 10 most important pages, already in clean Markdown format."
Jeremy Howard from Answer.AI proposed this back in September 2024. The idea spread fast. But whether it actually works? That's where things get messy.
What It Actually Looks Like
The format is deliberately simple — just Markdown. You start with your site name as an H1 header. Add a short description in a blockquote. Then organize your key pages under H2 headers like "Documentation," "Getting Started," or "API Reference."
Each link follows this pattern: [Page Title](URL): Brief description of what's here.
That's it. No complex syntax, no XML schemas, no configuration files. A developer can write one by hand in 20 minutes.
There's also llms-full.txt — a comprehensive version with all your documentation in one massive file instead of links. Cloudflare's version? 3.7 million tokens. Vercel's has been called "a 400,000-word novel." The logic? Why make the AI follow links when you can give it everything upfront?
Real example from Stripe.com llms.txt:
# Stripe
> Stripe is a technology company that provides financial infrastructure for businesses. Businesses of every size—from new startups to established public companies—use Stripe to accept payments online and in person, embed financial services, and create custom revenue models. For complete documentation in a single file, see [Full Documentation](https://stripe.com/llms-full.txt).
## Payments
- [Stripe Payments](https://stripe.com/payments): Accept payments online and in person globally with a payments solution built for any business—from scaling startups to global enterprises.
- [Stripe Payments features](https://stripe.com/payments/features): Learn more about Stripe Payments features.
- [Payment methods](https://stripe.com/payments/payment-methods): Acquire more customers and improve conversion by offering the most popular local payment methods around the world. Join millions of global businesses that launch and manage payment methods through Stripe.or Anthropic Claude Docs llms.txt:
# Claude Docs
## Docs
- [Kosten und Nutzung verfolgen](https://docs.claude.com/de/api/agent-sdk/cost-tracking.md): Token-Nutzung für die Abrechnung im Claude Agent SDK verstehen und verfolgen
- [Benutzerdefinierte Tools](https://docs.claude.com/de/api/agent-sdk/custom-tools.md): Erstellen und integrieren Sie benutzerdefinierte Tools, um die Funktionalität des Claude Agent SDK zu erweitern
- [Hosting des Agent SDK](https://docs.claude.com/de/api/agent-sdk/hosting.md): Bereitstellung und Hosting des Claude Agent SDK in ProduktionsumgebungenClean. Curated. Focused on the pages that matter most.
The standard also suggests offering Markdown versions of your pages by adding .md to URLs (page.html.md). This gives AI systems pure text without HTML parsing headaches.
Who's Actually Using This
The adoption list tells a story. It's not random small sites — it's developer tools, documentation platforms, and technical companies where AI coding assistants are critical.
Mintlify made the biggest impact. In November 2024, they enabled automatic llms.txt generation for every documentation site they host. Thousands of technical docs — including Anthropic, Cursor, Pinecone, and Windsurf — got llms.txt files instantly. This adoption suggests the industry sees value in structured AI-readable documentation.
Major tech companies show interesting implementation patterns. Anthropic has both llms.txt (8364 tokens) and llms-full.txt (481,349 tokens) covering their entire API documentation. Cloudflare organizes theirs by product, letting AI fetch only relevant context per service. NVIDIA split implementation between technical docs (1,259 tokens) and their main site (252,607 tokens). Stripe structures by product categories, using an "Optional" section for specialized tools like Stripe Climate.
Developer tools dominate. Supabase, Zapier, Modal, and dozens of others have adopted it. Makes sense — their users rely heavily on AI coding assistants, and accurate llms.txt files could improve the quality of AI-generated code suggestions about their platforms.
Three community directories actively track implementations: llms-text.com/directory lists 788+ verified sites, llmstxt.site shows hundreds with token counts, and directory.llmstxt.cloud categorizes by industry. These resources let you see real examples — valuable if you're considering implementation.
But here's where it gets weird.
The Uncomfortable Truth About AI Support
Not one major AI platform has officially committed to using llms.txt.
Zero. Zilch. Nada.
Google's John Mueller explicitly stated on Reddit and Bluesky: "No AI system currently uses llms.txt." OpenAI hasn't announced ChatGPT or GPTBot parse these files. Anthropic — despite publishing their own llms.txt — hasn't confirmed Claude's systems reference it during conversations. Google, Microsoft, Perplexity, and Meta? Radio silence.
Think about that. Websites are implementing a standard to help AI systems find their content, but the AI systems haven't confirmed they're looking for it.
Some SEO practitioners see OpenAI crawlers pinging llms.txt files every 15 minutes in their logs. But crawling a file doesn't mean using it for anything meaningful. Profound's GEO tracking shows Microsoft and OpenAI bots actively fetching both llms.txt and llms-full.txt, but this could just be exploratory crawling.
Could be nothing.
The optimistic interpretation? Platforms are quietly testing before making commitments. The skeptical view? They're never going to adopt it because better solutions already exist or will soon emerge.
Why Some Experts Call This a Waste of Time
The skeptics aren't holding back.
The skeptical argument comes down to this: There's no proven evidence that llms.txt improves AI retrieval, boosts traffic, or enhances model accuracy. And no provider has officially committed to parsing it.
Beyond that, there's a trust problem. Separate files enable manipulation. You could put different content in llms.txt than what humans see on your actual pages. This breaks the fundamental compact of trustworthy indexing.
Why would AI platforms trust it?
Research backs up the gaming concern. A paper called "Adversarial Search Engine Optimization for Large Language Models" demonstrated that carefully crafted content-level prompts can make LLMs 2.5× more likely to recommend targeted content. If websites can put special instructions in llms.txt that don't appear in visible HTML, abuse potential is massive.
Google's John Mueller has advised SEOs to "question everything" and catch misleading information before investing time in unnecessary work. The implication? Don't chase shiny objects without evidence.
The case rests on concrete realities:
- Zero official platform adoption 18 months after the proposal
- No confirmed cases of LLMs using llms.txt to improve responses
- No peer-reviewed studies showing effectiveness
- Documented potential for gaming and manipulation
Critics also point to what they call "misinformation loops." SEO tools like Rank Math and SEMrush flag missing llms.txt as site issues. This creates pressure to implement without evidence of value. Business owners anxious about AI visibility adopt it, reinforcing the perception that it matters — even though it might not.
It's a self-fulfilling cycle built on hope, not data.
Why Supporters Think You Should Implement Anyway
The counter-arguments focus on logical positioning and anecdotal signals.
Carolyn Shelby from Yoast frames it as future-proofing: "Ranking is no longer the prize — inclusion is." Her logic? AI systems need clarity and structure. Even if platforms haven't committed yet, providing that structure positions you for when they do.
Fair point.
The strongest supporting evidence comes from direct conversations. Windsurf highlighted that llms.txt saves time and tokens when AI agents parse documentation — a concrete technical benefit. Anthropic specifically requested llms.txt and llms-full.txt for their documentation on Mintlify, demonstrating clear interest from a leading AI company (even if not for their inference systems).
Google included llms.txt in their Agents to Agents (A2A) protocol, signaling at least experimental interest. The low-risk, potential-reward calculation appeals to early adopters: implementation takes 1-4 hours with no demonstrated downside if platforms eventually adopt the standard.
Jeremy Howard's vision extends beyond current reality. In March 2025, he stated: "It's 2025 and most content is still written for humans instead of LLMs. 99.9% of attention is about to be LLM attention, not human attention."
Bold claim. Maybe prescient, maybe premature.
This framing suggests llms.txt is less about immediate SEO gains and more about philosophical alignment with an AI-mediated future. Whether this vision materializes or proves premature is the billion-dollar question.
One case study from Springs Apps reported 20% increase in search engine visibility and 15% improvement in accurate AI query answers after implementation — though such data points remain rare and unverified by independent sources.
How It Compares to Standards That Actually Worked
Robots.txt succeeded because it solved a mutual problem with minimal cost. Websites needed crawl control. Search engines wanted respectful access. Everyone benefited. Major platforms (Google, Bing, OpenAI, Anthropic) officially honor it. It emerged from consensus and evolved through RFC 9309.
Schema.org succeeded because Google, Microsoft, Yahoo, and Yandex jointly developed it. Search engines demonstrably use it for rich results. Benefits are measurable — rich snippets increase click-through rates by documented percentages.
Sitemap.xml followed similar patterns — broad platform support preceded widespread adoption.
llms.txt? Has none of these characteristics yet.
It's a single-party proposal without W3C involvement or consortium backing. No major LLM provider has announced support. Gaming potential is significant. Most concerning, there's no demonstrated value: traffic improvements, ranking benefits, or accuracy enhancements remain theoretical.
The comparison reveals what typically makes web standards succeed: multi-stakeholder buy-in, clear and enforceable benefits, low gaming potential, integration with existing infrastructure, and explicit platform commitments.
llms.txt has... hope.
Where llms.txt does fit naturally is in the broader evolution toward AI-readable content. Just as websites adapted to mobile, social sharing, and voice search, they'll adapt to AI systems. The specific mechanism — whether llms.txt or something else — matters less than the underlying principle: content must be structured for machine understanding while remaining valuable for humans.
What Actually Works Today for AI Visibility
Regardless of llms.txt, certain tactics demonstrably improve how AI systems understand and cite your content.
Write direct answers to questions in the first paragraph. Use conversational language matching natural queries. Create strong heading hierarchies (H2, H3, H4) that make content scannable. Employ bulleted lists and comparison tables. Provide concrete examples with data and citations. Implement schema markup. Build internal linking that connects related concepts. Keep information up-to-date with clear timestamps. Demonstrate authoritative expertise backed by experience.
These aren't AI-specific tricks — they're good content strategy that happens to serve AI comprehension exceptionally well.
The convergence of human UX and AI optimization is the real insight.
Research into Generative Engine Optimization (GEO) shows that certain tactics improve AI visibility: adding authoritative citations, using clear statistics, including relevant quotes, structuring content with crisp headings, and writing in natural language.
Companies like Vercel report 10% of signups now come from ChatGPT due to GEO efforts, not traditional SEO. The shift is from "ranking" to "being referenced" — success means appearing in AI-generated answers, not just organic results.
Tools like SEMrush's Enterprise AIO, Profound's GEO tracking, and Ahrefs Brand Radar now monitor AI visibility — tracking brand mentions in AI responses, citation frequency, and sentiment. This data remains imperfect but improves monthly.
You know what matters? Being cited. Being referenced. Being trusted enough that AI systems pull your content when answering questions.
If You're Using Publii CMS: We've Got a Plugin for That
Good news — we've built a dedicated llms.txt Generator plugin specifically for Publii CMS that handles all of this automatically.
Here's what it does:
Automatic content selection. The plugin identifies your most valuable content based on featured posts, main tags, and recent updates. No manual curation needed (though you can override if you want).
Smart organization. It groups posts by their main tags to show your site's core topics, adds featured articles automatically, and includes recent posts that weren't captured elsewhere. Everything follows the official llms.txt specification.
Zero maintenance. The file generates during your normal Publii rendering process. Publish a new post? The llms.txt updates automatically. Mark something as featured? It gets added. No scripts, no manual updates, no forgetting.
Full control when you want it. Through a simple repeater interface, you can manually curate "Key Resources" — select specific posts or pages to highlight. Add optional notes for AI systems. Customize sections. Or just let the plugin do its thing.
Configuration takes under 10 minutes. After that, you never think about it again.
The plugin will be available soon through the Publii marketplace.
Add It. Here's Why.
Here's the truth: you should add llms.txt to your site. All sites. Small blogs, local businesses, niche content communities, everything in between.
The calculation is straightforward. There's literally no downside. The Publii plugin generates it automatically once, then maintains itself. It takes 10 minutes to enable. If AI platforms never adopt llms.txt, your site loses nothing — the file just sits there harmlessly. If they do, you're already there.
But there's a bigger reason.
Right now, traffic is fragmenting. Your small business blog isn't just competing for Google visibility anymore. People are asking ChatGPT questions that could lead them to your content. Perplexity is summarizing information with citations. Claude is answering questions while pulling from your pages. These platforms handle hundreds of millions of searches monthly, and the number keeps growing.
You're already visible to these systems. Google indexes your site, so AI platforms can crawl it. The question isn't whether they see you — it's whether they can find your best stuff quickly. An llms.txt file is basically a highlight reel. It says, "Here's what I'm actually good at. Start here."
Even if llms.txt never becomes official protocol, you're training AI systems to understand your site better. You're curating how machines read you. That's valuable regardless of what comes next.
The setup is genuinely painless with Publii. You're not writing complex XML or managing metadata spreadsheets. The plugin figures out your best content, organizes it, and handles updates. Add one line to your config file. Done. Move on with your actual work.
Why wait for evidence when you can hedge your bets for free?
Your Next Step
If you're running Publii, the answer is obvious: install the plugin and enable it. Configuration takes less time than your morning coffee. You'll spend more effort worrying about whether to do it than actually doing it.
For other platforms, evaluate your options. Some CMS systems already support llms.txt generation. Others let you upload it manually. The effort scales with your site's complexity, but it shouldn't be more than an hour of work for most sites.
Then continue doing what actually matters: write better content, improve your information architecture, maintain fresh material, build legitimate expertise. These fundamentals drive visibility in both human search and AI systems. llms.txt is an amplifier for content that already works.
The AI platforms will figure out their own adoption timelines. Your job is to make your content as accessible and well-organized as possible. llms.txt is one tool for that. But it's a tool that costs nothing to implement and might matter a lot.
So implement it.
The Bigger Picture
llms.txt sits at the intersection of hope and pragmatism. It addresses a real problem — how AI systems efficiently find your best content — but may or may not become the actual solution.
What's undeniable? Content discovery is increasingly AI-mediated.
ChatGPT, Perplexity, Claude, and Microsoft Copilot now receive enormous amounts of traffic from users worldwide. Google has launched AI Mode. Industry analysts forecast that AI-powered search could capture significant market share in coming years. These aren't distant possibilities — they're current realities reshaping how people discover information.
The llms.txt debate crystallizes a larger question facing content creators in 2025: How do you prepare for a future that's simultaneously inevitable in direction but uncertain in specifics?
The answer likely involves maintaining strong fundamentals while selectively experimenting with emerging standards, measuring everything possible, and staying flexible as the landscape evolves.
For now, llms.txt remains a proposed standard seeking adoption — promising in concept, uncertain in execution, and controversial in value. The next 12-24 months will determine whether it joins robots.txt and sitemap.xml as essential web infrastructure or fades as an interesting experiment that addressed a problem AI systems solved differently.
Either way, the attention it's generating reveals how seriously the industry takes AI-readable content optimization.
And that seriousness? Entirely justified.